· 6 min read
Printing the web, part 1: retrieving content from the web
This article is part of two articles that explain how to print web content into a book (a PDF file). In this first article, we'll create a script to scrape content from a web page.
This article is part of two articles that explain how to print web content into a book (a PDF file):
- Part 1: Retrieving content from the web (this article).
- Part 2: HTML and CSS for printing books.
Why printing the web as a real paper book? You may have your own reasons, but for me this is first and foremost because everything on the web has a short life. I have therefore printed an old blog that has had a significant influence on my life and whose content will probably disappear in the future (as everything does on the web). A book makes really sense for this.
I also wanted to “print Facebook” (!), or more precisely to print a documentary style Facebook page (where each article is a photo album) that I really like as a gift to my grandmother, who doesn’t use computers. Plus it’s much better to have it as a paper book (oh, and a book doesn’t track you too!).
I have created two kind of books from website content:
- A text book, created from a blog. Each chapter of the book is a blog post.
- Photo books, from the content that is regularly published on a documentary style Facebook page.
In this article, we are going to see some techniques to fetch content from the web to generate a book as an HTML file. In the second article I will show how HTML and CSS can surprisingly be very good tools to generate the printed book from the data we have fetched.
First step: Ask authorization!
For both the blog book and the Facebook page one, I wrote to the the authors to ask their permission to reuse their content for a book. I clearly exposed each time the reasons of my intention.
I explained the reasons as exposed in the introduction of this article. I also made clear that it was only for personal use, and that only one copy of the book would be printed. Both authors agreed without any problem.
I also sent them the generated PDF file so that they could have a glimpse of my work. The books I generated also include the name of the author of the content, along with necessary links.
Option 1: Getting the by crawling a website with a server-side script
The first step will be to get the content from the website you want to print.
For crawling a simple blog (WordPress like, with plain HTML files), I have created a small specific crawler to fetch articles from the website, make some changes on the fly to the HTML and merge all pages into an HTML page where each <article> tag is a chapter. These tools have been really convenient to achieve this with PHP:
- Symfony Console component to create a command with parameters.
- Symfony DomCrawler component to click links on the webpage and get the pages content. The library is very convenient for accessing nodes within the HTML page
- Symfony Filesystem to create files.
- Twig for rendering the generated book as an HTML file.
Option 2: getting the content with a script run in the browser + additional NodeJS scripts
For the Facebook webpage, it was a bit different. I had to fetch images from photo albums and then create an HTML page from all the albums I have fetched.
The 3 main steps are as follow:
- Generate a JSON document within the browser containing the information I need from the HTML content: kind of “retro API” 😀
- Download additional data like pictures and save them locally.
- Generate an HTML file representing the book from the JSON file and the local data.
1. Crawl the albums within the browser with a script
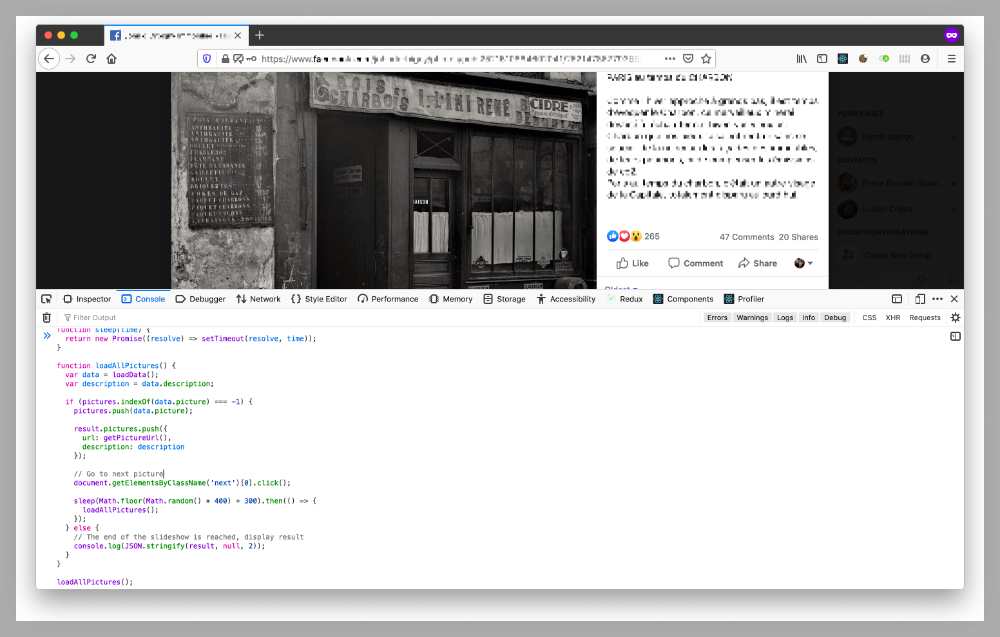
I have created a small JavaScript script to run within Firefox or Chrome dev console. The main steps of the script are as follow:
- Retrieve the album photo data by fetching content from the DOM. The data consists of the picture URL and its text description.
- Save that data into a JavaScript object.
- Click programmatically within the Facebook interface with
element.click()to browse to the next picture (see documentation on the MDN - Loop until the first picture is found again.
- Convert the JavaScript object to JSON (
JSON.stringify()call). - Display the output of the JSON in the console.
This is a plain JavaScript script that I run within the browser like this:
I encourage you to write your own script following (more or less closely) the steps that I have described above!
2. Download pictures
To download pictures of each album (represented as a JSON file) and save them in each directory, I created a small script with NodeJS that does the following:
- Parse the JSON file of each album.
- Download pictures and save them following a file tree convention.
My NodeJS helper to download a picture from its URL looks like this (it could be improved of course, but I am trying not to overengineer things here):
const fs = require('fs');
const http = require('https');
function downloadFile(url, filename, callback) {
if (fs.existsSync(filename)) {
console.log('🔶 File already exists... skipping.');
callback();
return;
}
const file = fs.createWriteStream(filename);
file.on('error', (err) => {
// Handle errors
fs.unlink(filename); // Delete the file async
console.log(`❌ ${err.message}`);
});
const request = http.get(url, (response) => {
if (response.statusCode !== 200) {
console.log('Response status was ' + response.statusCode);
return;
}
file.on('finish', () => {
file.close();
callback();
});
response.pipe(file);
});
request.on('error', (err) => {
// Handle errors
fs.unlink(filename); // Delete the file async
console.log(err.message);
});
}
exports.downloadFile = downloadFile;3. Generate the HTML file of the book with React
Now that we have the files stored locally and all the albums data, we need to generate the HTML file of the book.
A very convenient way is to do it with React, by providing the JSON file as a data source on the parent component. I then created the following components to separate things:
BookAlbumAlbum/Picture
The React script is run with NodeJS and saved as an HTML file by using server side rendering. Here is what the main script looks like
import React from 'react';
import { renderToString } from 'react-dom/server';
import { writeFile } from 'fs';
import Book from './components/Book';
import albums from 'book-data/albums.json';
function renderHtmlPage(reactDom) {
return `
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>Book</title>
<link rel="stylesheet" href="styles/book.css">
</head>
<body>
<div>${reactDom}</div>
</body>
</html>`;
}
const bookComponent = <Book title="My Book" albums={albums} />;
const reactDom = renderToString(bookComponent);
const res = renderHtmlPage(reactDom);
writeFile('./build/book.html', res, (err) => {
if (err) {
console.log(err);
}
console.log('The book was successfully generated!');
});